One busy day after school back in 2018, I was playing games on my computer while searching for music to play in the background on Youtube. Kpop was big on my school back then, so I gave it a try. From then on, I was hooked and became a fan. Twice was famous among my peers so I chose them as my first group to “stan.” Watching one of their performances on Youtube, I encountered a problem that I’m sure many of those who are new to Kpop are very familiar with, they all look the same.
Premise
To the untrained eye, all Kpop idols look the same. Take a look at the examples below.

Nayeon(left) and Mina(right)

Momo(left) and Jihyo(right)
On the video performance that I was watching, I mistook Mina for Nayeon and Momo for Jihyo. It sounds absurd at first, but I bet to some, especially those who aren’t particularly fond of Kpop (yet), would agree that they do look similar.
AI Solution
With this, I decided to create a facial recognition script that would label each member of Twice given a video. Using a pre-trained Siamese Network, embeddings for each member will be generated and an SVM classifier would be trained on these embeddings to predict the names of the members present in a particular frame of the video.
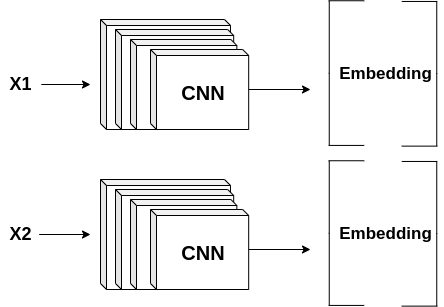
A Siamese Network
I won’t go deep in the technical discussion of how deep learning-based facial recognition works as this blog is generally about the applications of AI. In facial recognition, we are trying to learn a similarity function between images instead of a function directly mapping from input to class label. Directly mapping the input to its class label, such as in image classification won’t work because:
-
The training data for facial recognition is limited. Most likely, you will only have a few, if not a single picture of each person you want to recognize.
-
Let’s say you want to add another person to the list of people you want to recognize. Then, you will need to retrain the whole network.
By learning a similarity function, we are able to solve the two problems above. Now, in order to learn this similarity function, a Siamese Network is used. This network is composed of two (although it may be composed of 3 depending on your methodology for training the network) identical networks with the same weights as shown in the image above. These networks generate feature maps or embeddings or encodings, depending on what you want to call them, which will differentiate between the inputs by computing the distance between them. Ideally, similar inputs should have a small distance between them and different inputs should have a large distance.
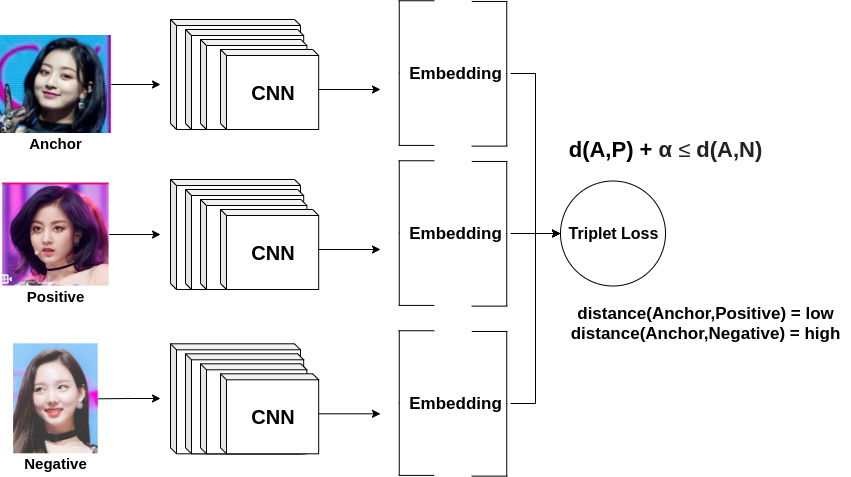
Training a Siamese Network
To train a Siamese Network, we input an anchor image, a positive image (an image with the same identity as the anchor), and a negative image (an image with a different identity as the anchor). There are two ways to treat this training task, by using a triplet loss or by treating it as a binary classification problem with logistic regression. I will discuss the triplet loss way. The formula for triplet loss is displayed above. Given the distance between the anchor and the positive (d(A,P)), and the distance between the anchor and the negative (d(A,N)), minimize the loss by minimizing d(A,P) and maximizing d(A,N).
Since I have used a pre-trained Siamese Network, all I have to do is just generate embeddings for each Twice member. Then, I will use a trained SVM with a threshold to output the name of the Twice member instead of using the distances through KNN.
If you want to go “deeper” (no pun intended) and learn more about Facial Recognition check out the following papers, videos and blogs:
- DeepFace, Facebook
- FaceNet, Google
- Facial Recognition, deeplearning.ai
- One Shot Learning, deeplearning.ai
- Siamese Network, deeplearning.ai
- Triple Loss, deeplearning.ai
- One Shot Learning with Siamese Networks using Keras, Harshall Lamba
- One Shot learning, Siamese networks and Triplet Loss with Keras, Eric Craeymeersch
- Machine Learning is Fun, Adam Geitgey
- PyImageSearch
Also, shoutout to the PyImageSearch blog above where I based some of my code on.
Clone this Github repo to follow along.
The Data
I scraped Google Images for pictures of each member using the google-images-download package. I made a python script wrapper for this package called, dataset.py. It takes an argument k as the keyword for the image search and n as the number of images to download. It will create a directory for each class label, in this case each Twice member, and store the downloaded images respectively. Its usage is shown below.
python3 dataset.py -k "Jihyo" -n 50
python3 dataset.py -k "Nayeon" -n 50
python3 dataset.py -k "Dahyun" -n 50
....
Next, I cleaned the downloaded images. Some downloaded images may be corrupted, which is unavoidable due to a variety of reasons, and some may be in GIF format which is not accepted by our algorithm so we need to pre-process these special cases.
import os
from PIL import Image
img_dir = r"data"
for classes in os.listdir(img_dir):
for file in os.listdir("data/"+classes):
if file.endswith(".gif") or file.endswith(".GIF"):
new_filename = img_dir + "/" + classes + "/" + file[:-4] + ".jpg"
Image.open(img_dir + "/" + classes + "/" + file).convert('RGB').save(new_filename)
os.remove(img_dir + "/" + classes + "/" + file)
file = file[:-4] + ".jpg"
print(file)
try :
with Image.open(img_dir + "/" + classes + "/" + file) as im:
print('ok')
except :
print(img_dir + "/" + classes + "/" + file)
os.remove(img_dir + "/" + classes + "/" + file)
Iterate through the images and check for GIFs. If the image is a GIF, save its first frame then, delete the file. This will allow us to still make use of the GIF by converting its first frame to a readable image format for the algorithm. After that, delete all corrupted files.
Run clean.py which implements the code above to clean the data.
python3 clean.py
Finally, manually check the data. Be sure that only one face is present at a given image. Crop-out unwanted faces and delete images not corresponding to the class label (the name of the Twice member). Its important to clean the data first before proceeding to training in order to produce a robust and accurate model.
Training
It is now time for training. First, let’s generate embeddings for each Twice member. To generate embeddings we only need the facial features of our images. With this, we need to crop our images, only including the face present in each image. We will do this using the hog face detector of dlib. Upon cropping an image, we generate an embedding by running our image through the CNN of the pretrained Siamese network which will be written to a pickle file.
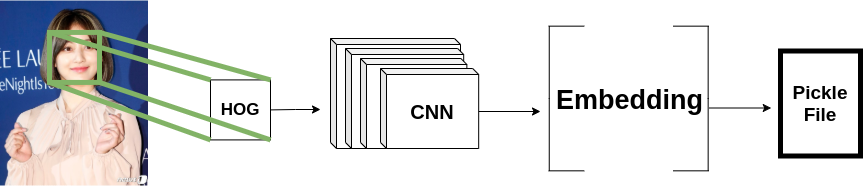
Run encode.py to generate embedings. It takes in an argument f for the path of the output pickle file that contains the embeddings. Usage is shown below.
python3 encode.py -f "encode.pickle"
Now that we have embeddings, let’s train an SVM classifier. This will take in the embeddings we produced in the previous step as training data and will output a prediction of which Twice member is present given a new embedding generated from an image.
def train_svm():
file_name = args.input
model_name = args.output
try:
data = pickle.loads(open(file_name, "rb").read())
encodings = data["encodings"]
names = data["names"]
except Exception as e:
exit()
clf = svm.SVC(gamma="scale", C=1.0, kernel="linear", probability=True)
clf.fit(encodings,names)
model = clf
print("[INFO] Labels", names)
print("[INFO] Successfully Trained the Network.")
with open(model_name, 'wb') as outfile:
pickle.dump((clf, names), outfile)
Using the svm classifier from the sklearn package, fit the embeddings with the respective labels from our generated pickle file.
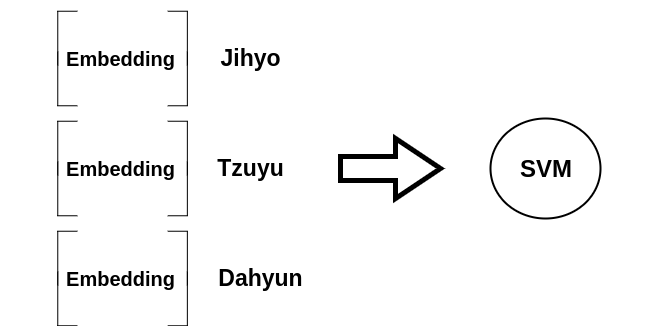
Run train.py to execute the code above. It takes in an argument i for the path of the embedding file and o for the output path of the model.
python3 train.py -i "encode.pickle" -o "model.pickle"
That’s it we now have a working model that recognizes each member of Twice.
Testing
Download a sample video to run our face recognition script on. Run video.py which takes in 5 arguments:
i- the input video to processo- the processed video pathm- the path to our model (the output of train.py)d- 0 or 1, whether to display the frame-by-frame processing or nott- optional / decimal value from 0-1, the threshold upon which to recognize a person
python3 video.py -i "twice.mp4" -o "processed.mp4" -m "model.pickle" -d 1 -t 0.7

This performs the pre-processing steps discussed in our training step. First, preprocess each frame and crop the detected faces of our hog face detector. Then, generate embeddings from these cropped faces through the CNN of our Siamese Network. The generated embeddings are fed to our SVM classifier which will output the names, respectively. Lastly, bounding boxes and labels are rendered onto the frame and the frame is written to a video.
Optional Step
Our processed video won’t have any audio because we have only written the frames from our original input video. This step involves the use of ffmpeg to extract the sound from our original input video and apply it to our processed video. You can install ffmpeg here. For Windows, make sure the executable file is in the directory of your repository. Then, execute audio.py. Its parameters are:
i- the Original input videop- the processed video from the previous stepo- the filename of the output videoa- the filename of the audio to be extracted (.mp3)
Its usage is shown below,
python3 audio.py -i "twice.mp4" -p "processed.mp4" -o "processed_with_audio.mp4" -a "audio.mp3"
The model performed well as shows below.
Output
It was fun for me to create an AI project for Kpop. I hope my fellow “once” can benefit from this project. How about you? Which group do you “stan”? Did you mistake a member for another? If so, then try to replicate what I have done with your favorite group and don’t be shy to share your project in the comments! Till the next post.