Two events inspired this post. On April 24, 2020, a new version of the Yolo object detection algorithm was released and on May 28, 2020, the president of the Philippines made it official that the capital, Metro Manila, would be placed under General Community Quarantine(GCQ) from the previous Modified Enhanced Community Quarantine(MECQ) amidst the Convid-19 Pandemic. In this blog post, I will demonstrate how Deep Learning can help in monitoring distancing behaviour of the general public.
Premise
On June 1, 2020, the National Capital Region will be under General Community Quarantine from the previous Modified Enhanced Community Quarantine easing the restrictions imposed to the public. With this, those who are working for the industries approved by the government will be able to go back to work. As the number of cases in the Philippines is not showing signs of going down, I am deeply worried for those who will be exposed in public. For this reason, I tried to think of a system that could help in monitoring the public for their own safety.
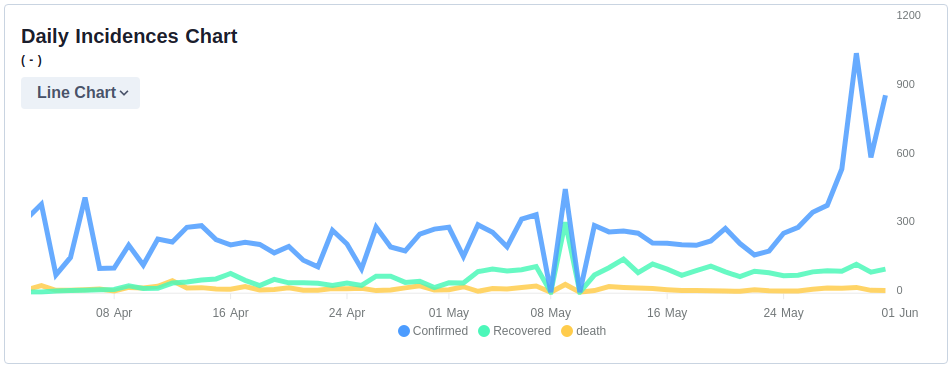
Covid Cases in the Philippines over Time. Image source
AI Solution
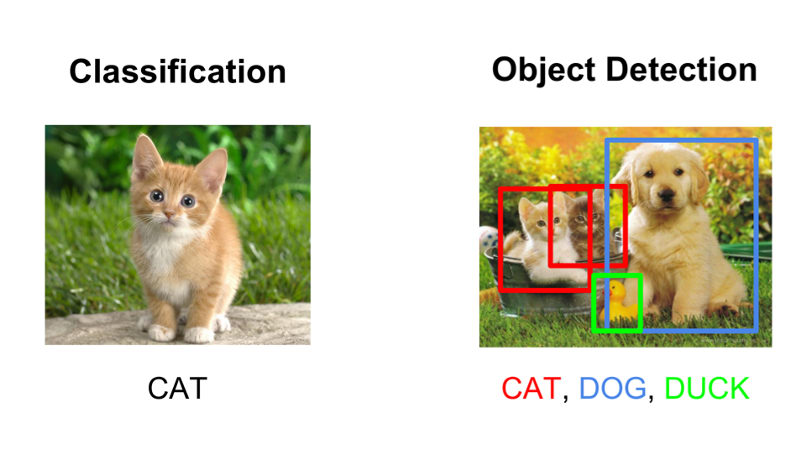
Object Detection is a Computer Vision task where the goal is to identify and locate instances of objects in images. It is different from image classification which only outputs the classification label which has the highest probability computed. In object detection, we classify and locate object instances in an image by locating bounding boxes that accurately surround the object instances.
There are many Deep Learning Algorithms for object detection that provide a trade-off between accuracy and speed. Last year, one of the tasks I had at work was to try and benchmark these object detection algorithms against each other and find out what was the best. I compared the three most popular object detection algorithms, SSD, Faster-RCNN and Yolo. I found out that generally, Faster-RCNN was the most accurate but also the slowest in terms of inference time among the three. Yolo was the least accurate but was the fastest and SSD was in the middle.
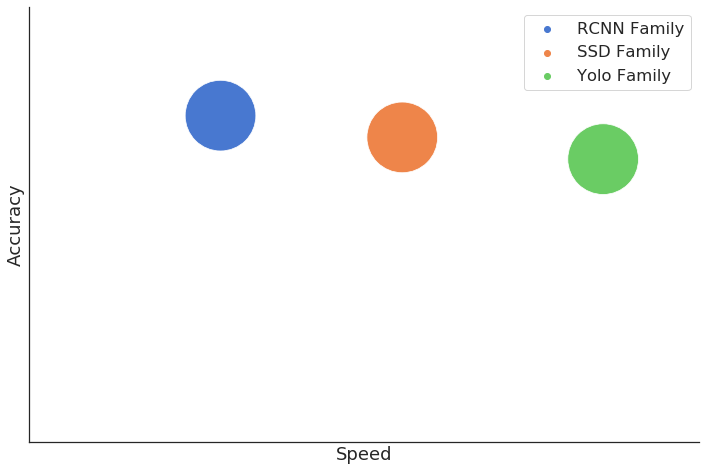
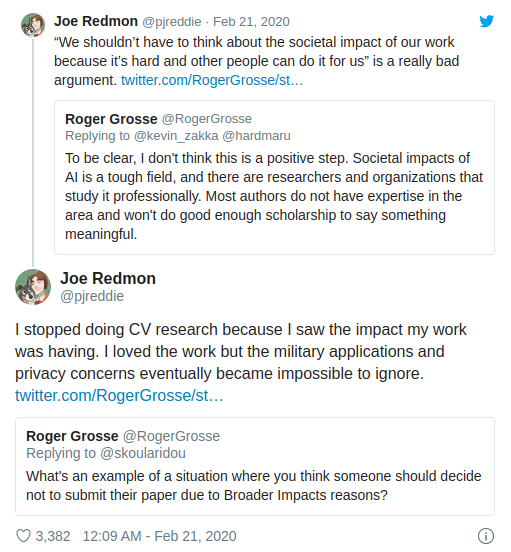
However, given the significant lead of Yolo in terms of speed compared to RCNN and SSD and its acceptable accuracy results, it bacame my go-to algorithm when it comes to object detection. Unfortunately, the original creator of the Yolo algorithm, Joseph Redmon, announced on Twitter just this Febuary that he was leaving the field of Computer Vision Research because of the potential negative impacts that can be brought about by his work. This actually made me quite sad as Yolo was my favorite object detection and I would have liked to see the improvements that could be achieved with further development of the algorithm through the years. Nonetheless, I understood his point and I do think that we should improve the dialogues among researchers and leaders about the AI ethics and responsibility.
Last April, while I was casually browsing the internet, it came to my surprise that YoloV4 was released. I thought to myself that Joseph might have come back to the field of research to continually improve the Yolo algorithm. To my surprise, YoloV4 had been developed by an entirely new set of researchers, Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. In my opinion, it’s nice that people are willing to continue the work of others in order to further the field of AI. I think of it as like sitting on the shoulders of giants.
To check out what’s new in YoloV4, refer to the following:
- The YoloV4 Paper
- The YoloV4 Repository
- YOLOv4 — Superior, Faster & More Accurate Object Detection (Medium), Ritesh Kanjee
YoloV3 was already the fastest object detection algorithm when it was released. Now, YoloV4 builds upon YoloV3 and improves its accuracy and speed by a considerable margin. With this, I wanted to try YoloV4 and use it on a project. When the president of our country announced that the National Capital Region would be under General Comminity Quarantine, easing the restrictions imposed to the people, I wanted to demonstrate how object detection algorithms could be utilized in monitoring the distancing behaviour of people in public places.
Development
First, I had to install YoloV4 onto my system. I use Ubuntu 18.04 as my development system which made it easy for me to install the algorithm. Yolo was originally written in an open-source neural network framework called Darknet. It is written in C and CUDA and serves as the basis of YOLO. Also, it is written by Joseph Redmon himself. As such, YoloV4 is also implemented in Darknet. I have tried a Tensorflow implementation of YoloV4 but I could not get the same original performance in the Darknet version. Refer to this guide to install YoloV4 and Darknet on your system.
In the repository of YoloV4 by the authors, there is a python file for processing videos and writting the processed videos to an output file called darknet_video.py. However, the output file has the same resolution as the input size which YoloV4 is configured to accept which means that upon resizing the input video for object detection, the output is not rescaled back to the original resolution resulting in a much smaller output resolution.
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # Get the original width and height
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # of the input video
scale_x = width/darknet.network_width(netMain) # Compute the sclale ratio of the original resolution
scale_y = height/darknet.network_height(netMain) # and the processing resolution of YoloV4
scale = (scale_x, scale_y)
def scale_back(detection, scale):
x, y, w, h = detection[2][0],\
detection[2][1],\
detection[2][2],\
detection[2][3]
x *= scale[0] # Multiply the x and y coordinates
y *= scale[1] # by the scale
w *= scale[0]
h *= scale[1]
xmin, ymin, xmax, ymax = convertBack(
float(x), float(y), float(w), float(h))
return (xmin, ymin, xmax, ymax)
Since we are doing social distance monitoring, we are only interested in pedestrian/person detection. YoloV4 was trained on the Common Objects in Context(COCO) Dataset which has 80 classes therefore, we need to “prune” the detections made by the mode.
def prune_and_scale(detections, scale):
pruned_detections = []
for detection in detections:
if detection[0] == b'person': # Check if the label is person
scaled_detection = scale_back(detection, scale)
pruned_detections.append(scaled_detection)
return pruned_detections
After “pruning” the detections, we now have to compute the distances between each and every detection that we have but first we need a point of reference for each detection. Each detection consists of four points constituting to a bounding box. I have chosen the midpoint of the two bottom points to make the computation of distances height invariant.
def get_midpoint(detection):
x = (detection[2] + detection[0]) / 2
y = detection[3]
return (x,y)

Then, we compute the distances between each and every detection with respect to our chosen point of reference. Now, there are many ways of inferring real-world distance from an image captured by a single camera with reliable accuracy to some extent. As an introductory project to person monitoring, I have gone the simple route explained below.

I divided the image into three zones with respect to the y axis. Relative distances in images captured by cameras tend to be warped. The closer objects are to a camera, the bigger they are. Consequently, the farther objects seem to be smaller. With this, relying on a single camera can be challenging to estimate the actual size and distance of objects in images. CCTV cameras are usually situated in high elevation which alleviates the effect of warping to some extent. With this, I estimated the conversion value of the real-world distance 6ft. to image pixels. Then, since farther objects seem to be smaller, I divided the image into three with respect to their heights and assigned scale values for the distance measure accordingly. The further the person is, the less its scale value is.
def compute_distance(detections, height):
offenders = []
zones = height / 3
threshold = args["threshold"]
for i,d1 in enumerate(detections):
m1 = get_midpoint(d1)
for j,d2 in enumerate(detections):
if i != j:
m2 = get_midpoint(d2)
distance = math.sqrt((m1[0]-m2[0])**2+(m1[1]-m2[1])**2)
if (m1[1] < zones or m2[1] < zones) and (m1[1] > 0 or m2[1] > 0):
scaler = 0.5
elif (m1[1] < zones*2 or m2[1] < zones*2) and (m1[1] > zones or m2[1] > zones):
scaler = 0.8
else:
scaler = 1
if distance < (threshold*scaler):
offenders.append((i,j))
return offenders
Lastly, I included a people counter that detects overcrowding with respect to a set threshold.
if len(detections) > 5:
cv2.putText(img,
"People Counter {} | Overcrowded!".format(len(detections)),
(5, 30), cv2.FONT_HERSHEY_SIMPLEX, 1,
[255, 0, 0], 2)
else:
cv2.putText(img,
"People Counter {}".format(len(detections)),
(5, 30), cv2.FONT_HERSHEY_SIMPLEX, 1,
[0, 255, 0], 2)
Testing
As you can see, the system performs relatively well. I adjusted the conversion value for the distance and the scale multiplier for each of the zones for each video with respect to the position and elevation of the camera in the video. However, further calibration is required and more improvements can be implemented. The system can detect distance to some extent, however, the question of is the distance really 6 Ft. remains to be answered.
In addition, we can see the system performing at 15-20 frames per second(FPS) using my GTX 970 GPU while using an input resolution of 416x416 for YoloV4. Reducing the video resolution and the input resolution will greatly increase the speed of the model.
Deployment Plan
Now that we have a prototype how can such system be productionalized and utilized by the public? I have specifically chosen YoloV4 for this project because of its significant advantage in terms of speed compared to any other algorithm. This means that this system can run in real-time even with limited hardware.

Theoretically, we could take the live video feed from a CCTV camera and feed it to a microcomputer (NVIDIA Jetson, Raspberry Pi, etc…) where the algorithm will process the video. Another option would be to have a dedicated server connected to multiple CCTVs for multiple video processing. A speaker could also be connected to the system to alert the people if they have violated the social distancing rule.
Further Improvements
As discussed earlier, there are many ways to infer real-world distance from images captured by cameras with accuracy to some extent. Researchers and engineers from Landing AI, a startup founded by Andrew Ng, calibrated the monocular view of a camera to transform it into a bird’s-eye (top-down) view. According to their blog post, “This assumes that every person is standing on the same flat ground plane. From this mapping, we can derive a transformation that can be applied to the entire perspective image. … During the calibration step, we also estimate the scale factor of the bird’s eye view, e.g. how many pixels correspond to 6 feet in real life.” According to another blog post by Aqeel Anwar who used the same method as Landing AI, “This bird eye view then has the property of points (which are same number of pixels apart) being equidistant no matter where they are. All it needs is a multiplier that maps the distance between two points in pixels to distance in real life units (such as feet or meters).”
Check out their blog posts here:
Secondly, the YoloV4 model I used was trained on the COCO dataset with 80 classes. Though the classes include “people/person” for pedestrian detection, it would be better to retrain the classifier to only include pedestrian as a class to make calculations faster. Also, I used an input resolution of 416x416 for YoloV4. Using a lower resolution coupled with quantization would greatly increase the speed of the algorithm.
Conclusion and Implication
With the current situation brought about by the pandemic, strict social distancing and good personal hygiene must be exercised by the people to avoid the spread of the disease. It is amazing to see that we can utilize Artificial Intelligence to help in monitoring and enforcing these rules. Last April, a new iteration of the Yolo object detection algorithm was released which brought about improvements in accuracy and speed. It was created by a new set of authors. I find it inspiring that people are willing to take up the work of others in order to improve and push the field of AI even further. However, with the big advancements in AI, continued dialogue about AI ethics, privacy and responsibility must also be prioritized. It is in my best hope that this pandemic end in the soonest of time. For now, let us all keep safe in the safety of our homes and if there is a need to go outside, may we abide by the rules and practice good hygiene. Lastly, I implore those who are privileged enough to help those who are not and to save not only for themselves but also for those who are less fortunate. Til the next post!