When I was a kid, I used to watch an anime called Naruto. It was a show which followed the adventures of Naruto, the main protagonist who was a ninja. In naruto, ninjas possesed “chakra” that allowed them to perform ninja jutsus or techniques. To use these techniques, they had to perform hand seals or hand signs which allowed their chakra to manifest as techniques. As a kid, I used to mimick these hand signs and scream out the techniques associated with them but I never really knew any of the hand signs. I just randomly made them up.

Premise
There are 12 basic hand signs or hand seals, each one named after an animal in the Chinese Zodiac. To be honest, I only know how to do one and I would try to make random hand signs to compensate for the other 11. Through the recent rise of Deep Learning, Computers are now able to “see” with accuracys even beating “human-level” performance. With this, I decided to create an application that would classify the twelve basic hand signs given an image.

The 12 Hand Seals
AI Solution
I framed this problem as an image classification task. Given an image, our model will output a label corresponding to the 12 basic hand signs. I used a Convolutional Neural Network/CNN which is the type of Neural Networks used for image data primarily because:
- Less paramters compared to Feed-Forward NN
- Better at capturing spacial information
- Parameter sharing
- Sparsity of connections
These are all made possible by the process of convolution.
I used two CNN architectures, namely, MobileNetV2 and Squeezenet which are architectures that I used on my thesis. I chose both networks because I needed a network that could run almost in real-time when classifying images and achieve fairly accurate results. Both networks presented a good trade-off between speed and accuracy in our testing compared to more substantial networks like Inception and ResNet, where Squeezenet was faster in inference time but less accurate while MobileNetV2 was more accurate but had slightly slower inference time.
I made a jupyter notebook discussing Convolutional Neural Networks in detail based on the Deep Learning Specialization Course that I took. Comment down below or contact me if you’d like a copy or a dedicated blog post about CNNs.
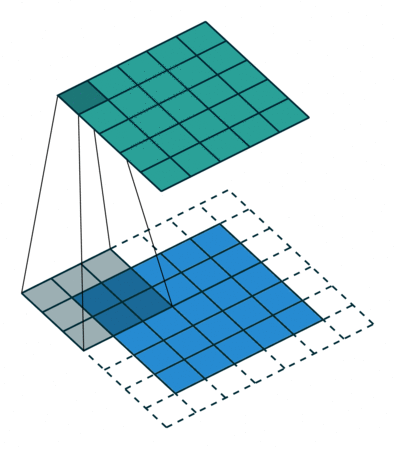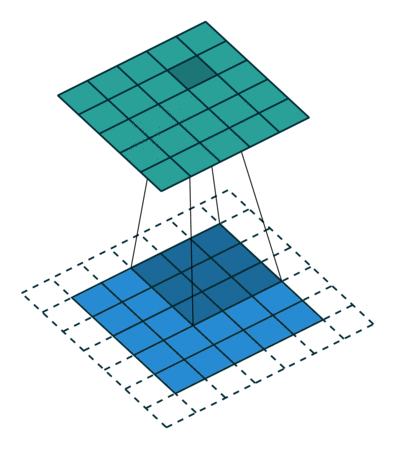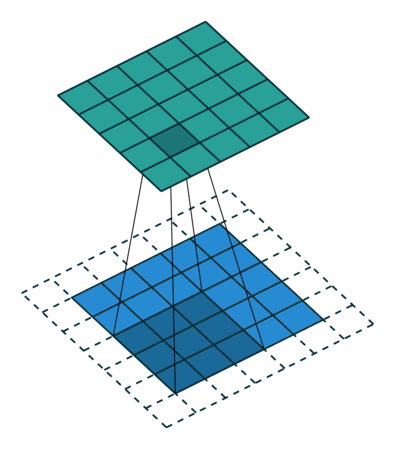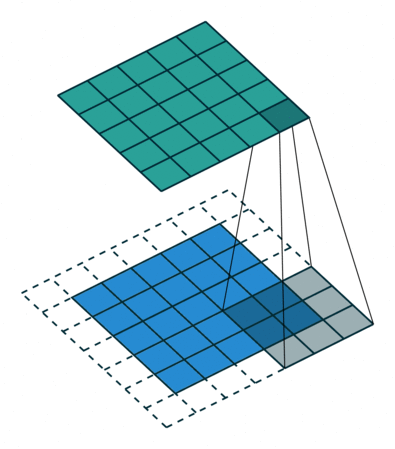
A Convolutional Filter
For now, here are some supplementary material if you want to dig deeper:
In addition, I included three techniques/jutsus that will render on the screen through the appropriate ordering of hand seals just to spice things up.
The github repository for this project can be found here
The Data
Sadly, there are no publicly available datasets for Naruto Hand Seals in the internet but that won’t stop me from making this project into reality. I downloaded images from the internet of the 12 hand seals with a mixture of anime and real-life examples. Then, I searched for videos in youtube of people doing the 12 hand seals and manually captured the frames that involved the hand seals. However, doing all these only got me 100 images for each hand seal which wasn’t enough. With this, I got the idea of creating my own data by capturing videos of myself doing the hand seals and getting each frame of the video. I created a python script that captured each frame in a video feed wherein that video feed was of me doing the 12 handseals. This got me to about 250 images per class which I augmented to get more examples. Lastly, I included an unkown class with a mixture of background and blurry hand seals images to account for hand seal transitions and background video feed. A sample of the data is shown below.
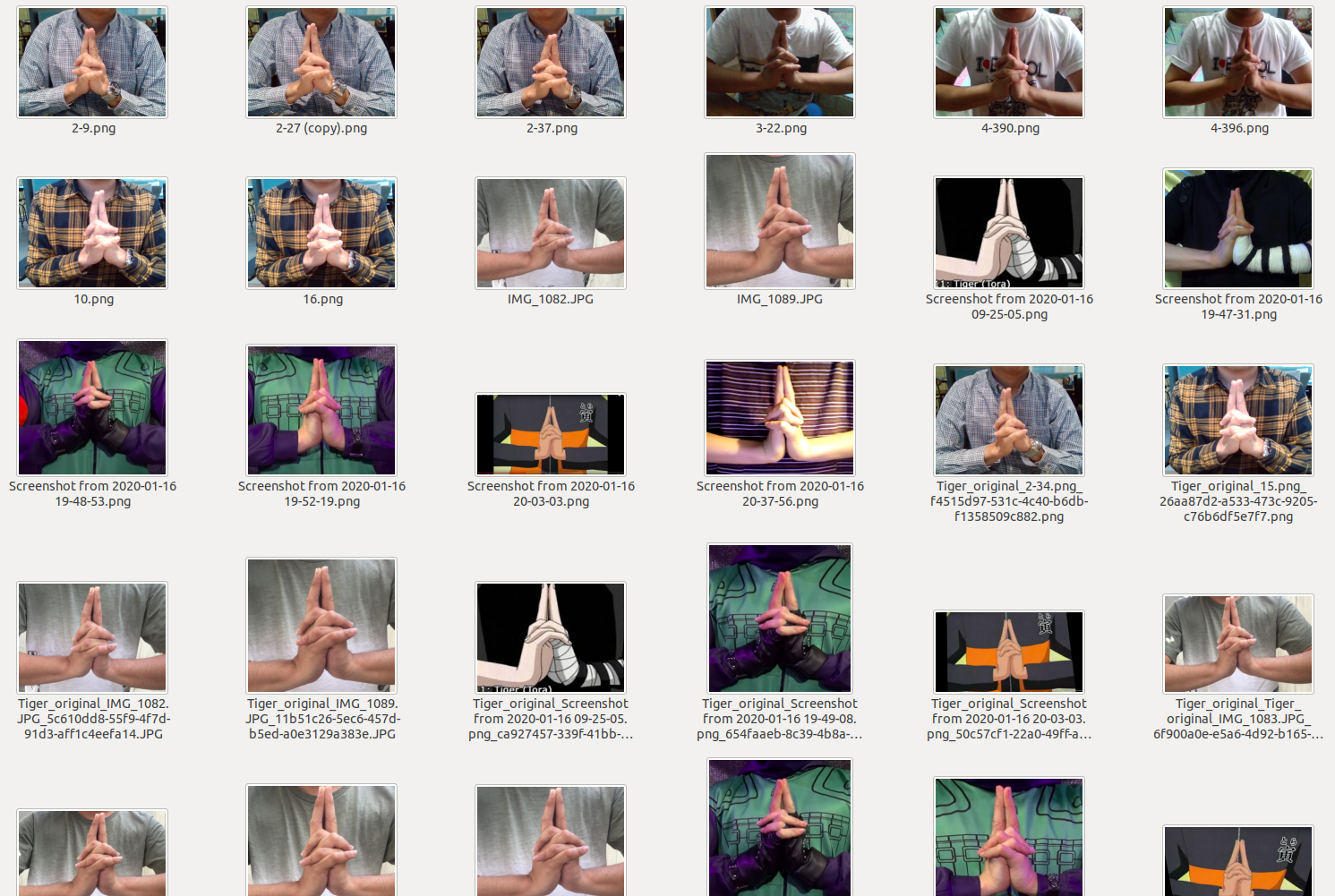
Sample of the Dataset with Label Tiger
Training
I trained the network for 50 epochs with the Adam optimizer and categorical cross-entropy loss. I performed transfer learning by fine-tuning the MobileNetV2 and Squeezenet models pre-trained on the imagenet dataset to my Naruto Hand Seals Dataset. I also discovered that freezing only 75% of the network helped in increasing validation accuracy. Freezing 90%-95% of the network didn’t give much overhead in learning the dataset, thus, resulting in less validation accuracy. This was because my dataset was relatively different from the prior dataset which was imagenet. My next blog post will be about my workflow on this project. Basically, I used Data Version Control to manage my datasets and Weights and Biases to manage my training experiments.
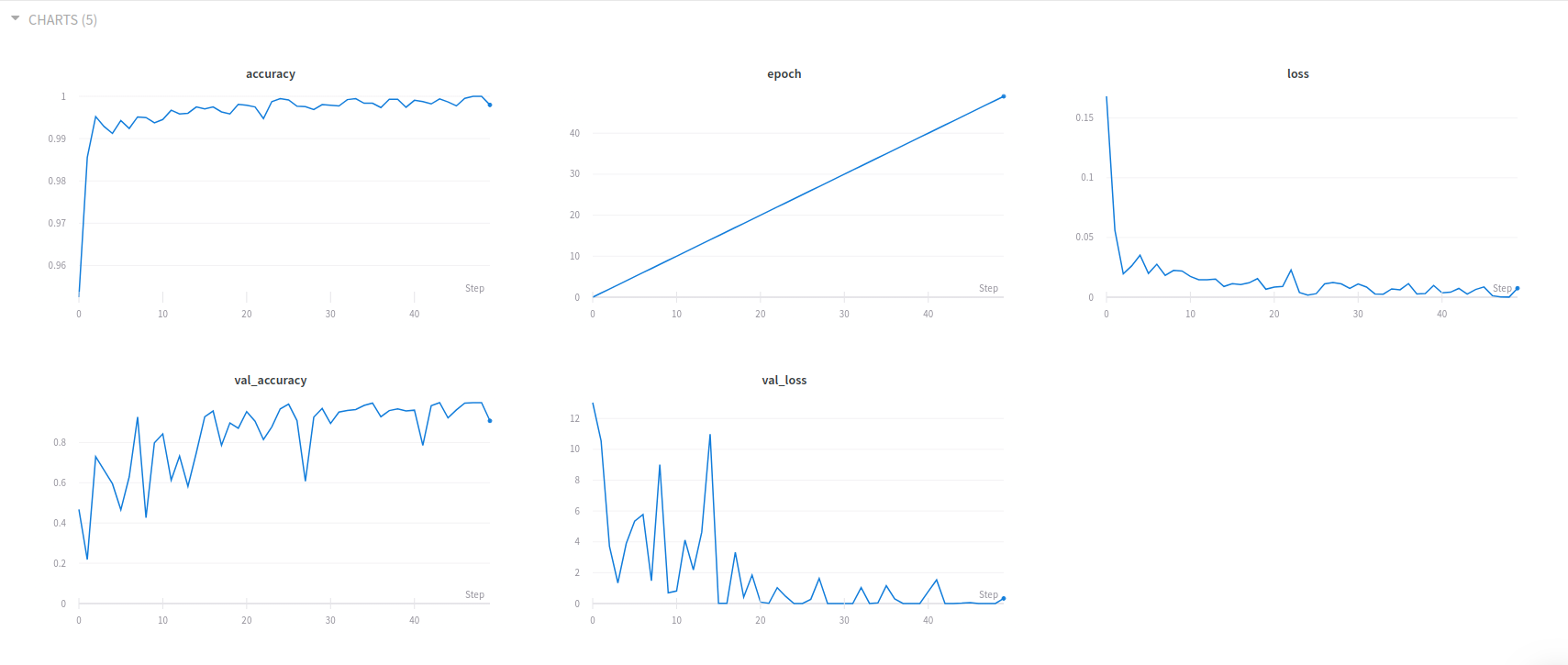
A Training Experiment Dashboard of Weights and Biases
Inference Methodology
OpenCV will instantiate an object that gets input from a webcam and feeds the video to python. If each frame of the video feed will undergo model inference, the system might be sluggish due to the number of inferences per second. This is why I have implemented a skip-function, where the system only predicts every three frames of the feed. Another problem is the transition of hand seals. When transitioning to a different hand seal, the frame might be blurred resulting in an unknown classification or a misclassification at worst. I made a moving smoothing function that stores 5 consecutive predictions in an array and the most frequent prediction is chosen as the final prediction. After that, the array is cleared and 5 consecutive predictions are processed again.

Samples of Hand Seal Transition
Testing
The model performed good as seen below. It classifies the frames in the video feed from my webcam in almost a real-time fashion while achieving accurate classification results.
You can test the system by running run-webcam.py from the github repository. It needs a model argument to specify the model to be used. You can use mb.h5 for MobileNetV2 or sq.h5 for Squeezenet. Run the script as follows:
python3 run-webcam.py -m "mb.h5"
You can also perform techniques by performing hand seals in sequence. Try the sequences below and see your technique rendered on the screen.
- Chidori: Ox -> Hare -> Monkey

Chidori
- Fireball Jutsu: Snake -> Ram -> Monkey -> Boar -> Horse -> Tiger

Fireball Jutsu
- Summoning Jutsu: Boar -> Dog -> Bird -> Monkey -> Ram

Summoning Jutsu
If you have trouble doing the hand seals yourself, I have mapped the hand seals to keyboard shortcuts as follows:
1-> Bird2-> Boar3-> Dog4-> Dragon5-> Hare6-> Horse7-> Monkey8-> Ox9-> Ram0-> Rat--> Snake=-> Tiger
I also included utility functions for clearing hand seals, if ever you make a mistake in ordering the hand seals for techniques, and for quiting the program.
w-> Clear Hand Sealsq-> Quit
Further Improvements and Assumptions
The model performed well, although, more training data is needed to produce a truly robust and generalized model. While training my model, I had an idea to convert the images to grayscale and train my model with those images. However, I realized that I would not be able to use transfer learning because the data used to train the model before were colored (the imagenet dataset) so I did not go on with my plan.
The general idea behind converting the images to grayscale were based on face detection. In detecting faces, we don’t really need color information. In the case of the Histogram of Oriented Gradients (HOG) algorithm, we only need the direction of brightness (low to high) of the pixel values of the image. Using a CNN, I assumed that the network would learn a similar function that didn’t need color information to classify hand seals, however, my lack of training data hindered my experiment. I hope to try this approach in a future blog post though, once I have the time.
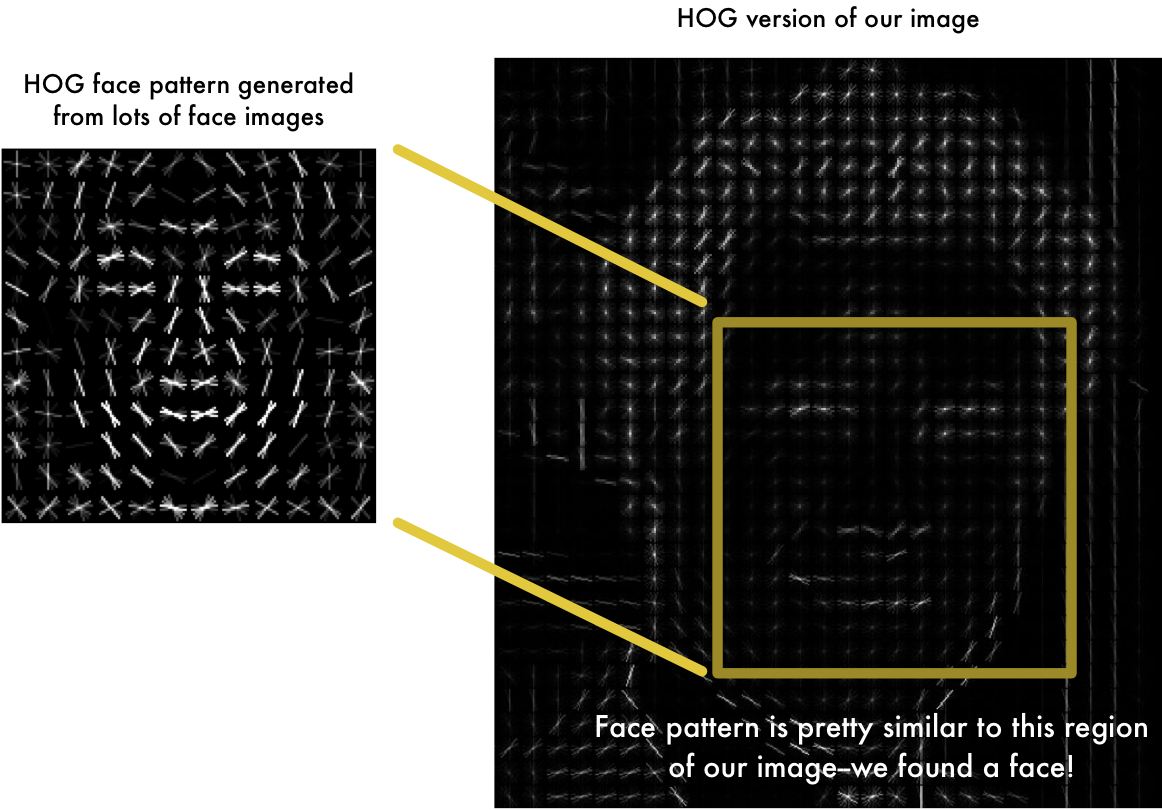
Face Detection Example
Conclusion
With the recent resurgence of Deep Learning, computers have gotten better in perceiving different types of inputs. In this project, I demonstrated the capability of computers to “see”. Also, it was fun to do a project with no publicly available dataset. It forced me to be resourceful by scraping the internet and creating my own data. In the next blog post, I hope to walk you through how I made this project into fruition by discussing my personal machine learning workflow. Till the next post!